爬取百度实时热点并进行数据分析 |
您所在的位置:网站首页 › 百度热力图怎么打开 网页 › 爬取百度实时热点并进行数据分析 |
爬取百度实时热点并进行数据分析
|
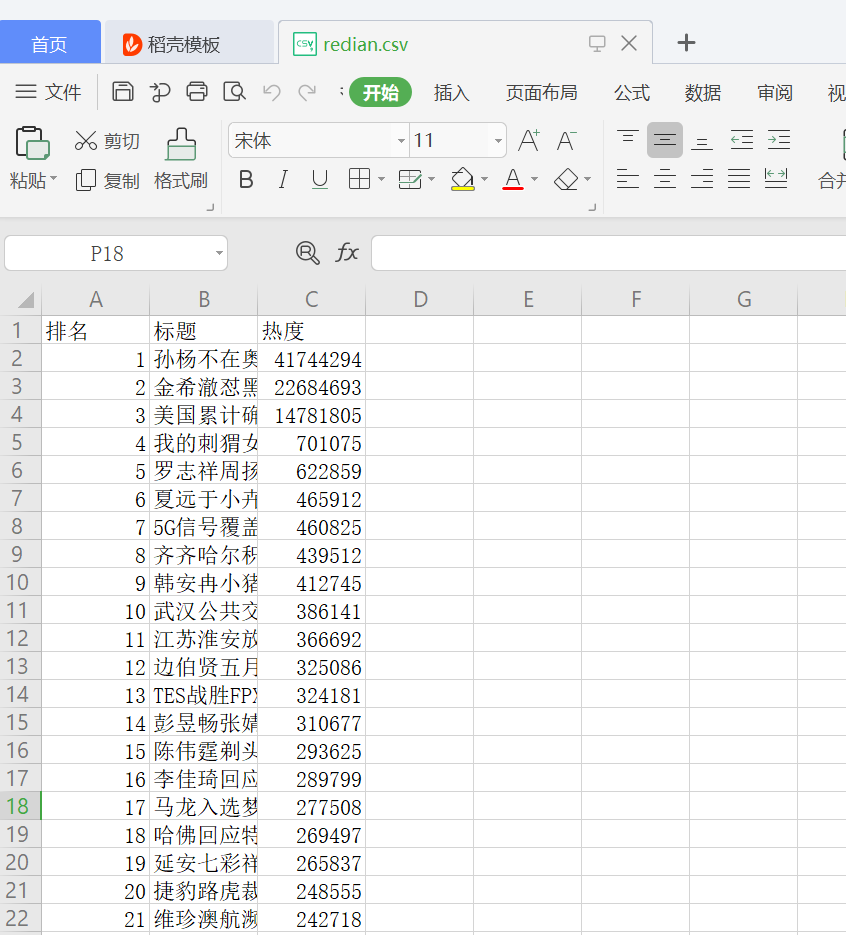
一、主题式网络爬虫设计方案 1.爬虫名称:爬取百度实时热点 2.爬虫爬取的内容:百度实时热点排行榜的排名,标题,热度。 3.爬虫设计方案概述:用requests.get(url)命令向服务器提交请求,然后将响应的网页信息交给BeatifulSoup库解析,获取自己想要的内容。然后使用pandans保存数据,并生成csv文件。然后读取文件,清洗数据,数据分析与可视化,最后用最小二乘法分析两个变量之间的相关系数并建立变量之间的回归方程。 二、主题页面的结构特征分析 1.主题页面的结构与特征分析:观察发现每个标题的各个元素是一个个td被包装在一个tr标签里面,每一个标题都是一个tr,排名 :td class="first";关键词:td cass="keyword";搜索指数:td class = "last"。 2.Htmls页面解析 1.数据爬取与采集 import requests from bs4 import BeautifulSoup import bs4 #定义获取页面信息函数 def get_html(url,headers): r = requests.get(url,headers=headers) r.encoding = r.apparent_encoding#解决中文字符编码问题 return r.text #建立空表格 准备数据填充 name=[] rank=[] times=[] #定义解析页面函数 def get_pages(html): soup = BeautifulSoup(html,'html.parser')#使用BeautifulSoup库解析页面 all_topics=soup.find_all('tr')[1:] #获取标签内容 for each_topic in all_topics: topic_times = each_topic.find('td',class_='last')#热度 topic_rank = each_topic.find('td',class_='first')#排名 topic_name = each_topic.find('td',class_='keyword')#标题目 if topic_rank != None and topic_name!=None and topic_times!=None: topic_rank = each_topic.find('td',class_='first').get_text().replace(' ','').replace('\n','') rank.append(topic_rank)#填充数据 topic_name = each_topic.find('td',class_='keyword').get_text().replace(' ','').replace('\n','') name.append(topic_name) topic_times = each_topic.find('td',class_='last').get_text().replace(' ','').replace('\n','') times.append(topic_times) tplt = "排名:{0:^4}\t标题:{1:{3}^15}\t热度:{2:^8}" #定义主函数 def main(): url = 'http://top.baidu.com/buzz?b=1&fr=20811' headers= {'User-Agent':'Mozilla/5.0'}#表头信息 html = get_html(url,headers) get_pages(html) if __name__=='__main__': main() print(times) print(name) print(rank) #使用pandans保存数据 from pandas.core.frame import DataFrame D={"排名":rank, "标题":name, "热度":times} data=DataFrame(D) print(data) #生成CSV文件 filename="redian.csv" data.to_csv(filename,index=False)
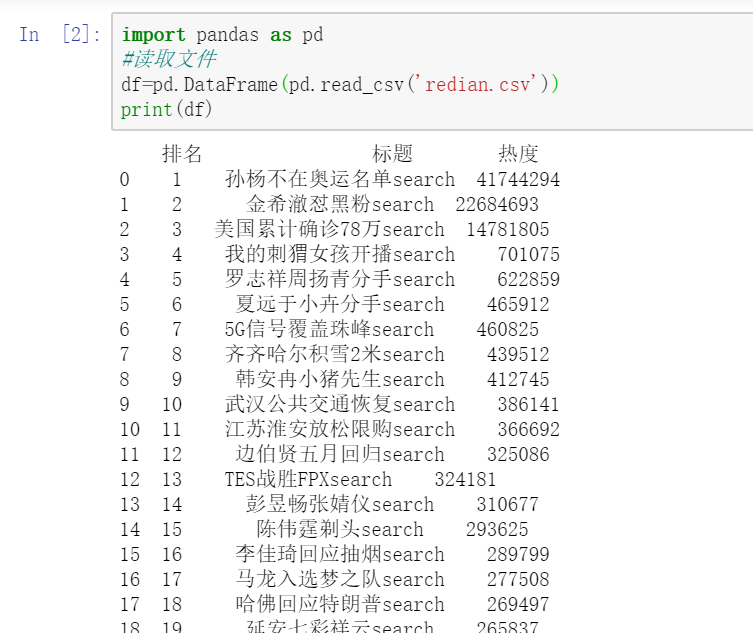
2.对数据进行清洗和处理 (1)、读取文件 import pandas as pd #读取文件 df=pd.DataFrame(pd.read_csv('redian.csv')) print(df)
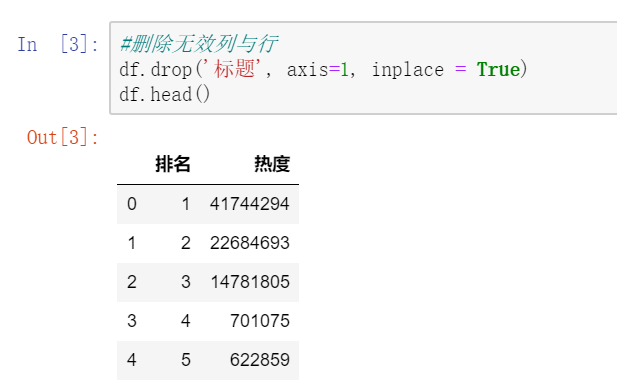
(2)、删除无效列与行 #删除无效列与行 df.drop('标题', axis=1, inplace = True) df.head()
(3)、重复值处理 #重复值处理 df.duplicated()
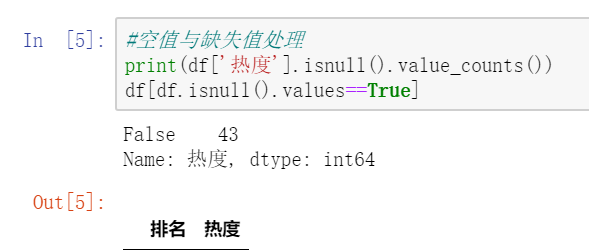
(4)、空值与缺失值处理 #空值与缺失值处理 print(df['热度'].isnull().value_counts()) df[df.isnull().values==True]
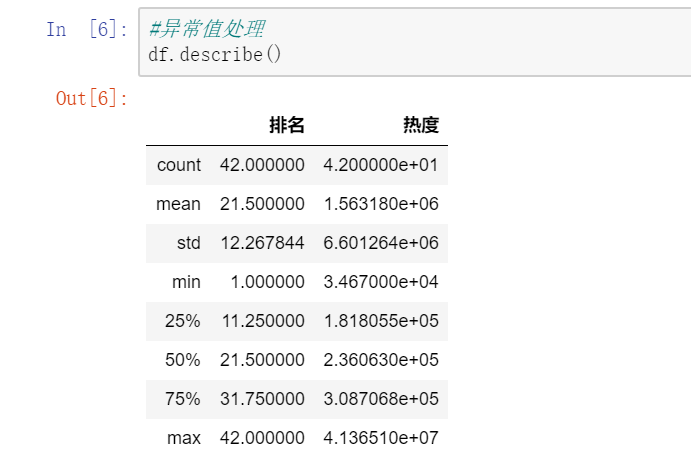
(5)、异常值处理 #异常值处理 df.describe()
3.数据分析与可视化 #数据处理与可视化 import numpy as np import pandas as pd import sklearn from sklearn.linear_model import LinearRegression X=df.drop("排名",axis=1) predict_model=LinearRegression() #训练模型 predict_model.fit(X,df['热度']) #判断相关性 print("回归系数为:",predict_model.coef_)
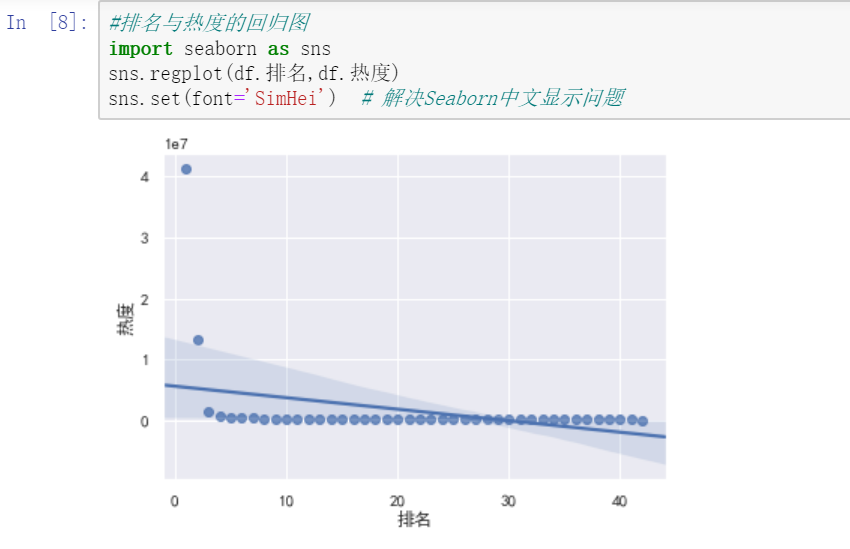
回归图 #排名与热度的回归图 import seaborn as sns sns.regplot(df.排名,df.热度) sns.set(font='SimHei') # 解决Seaborn中文显示问题
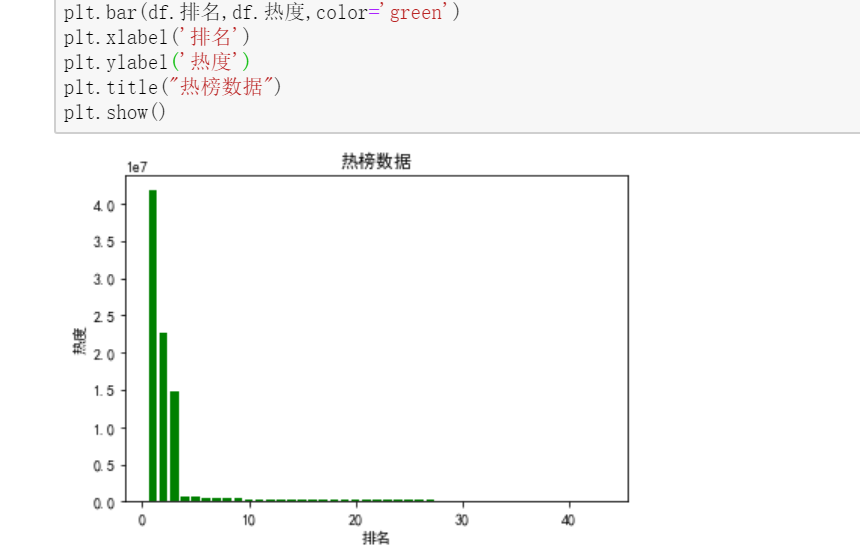
柱状图 #绘制柱状图 import pandas as pd import numpy as np import matplotlib.pyplot as plt plt.rcParams['font.sans-serif']=['SimHei'] #用来正常显示中文标签 plt.rcParams['axes.unicode_minus']=False #用来正常显示负号 plt.figure() plt.bar(df.排名,df.热度,color='green') plt.xlabel('排名') plt.ylabel('热度') plt.title("热榜数据") plt.show()
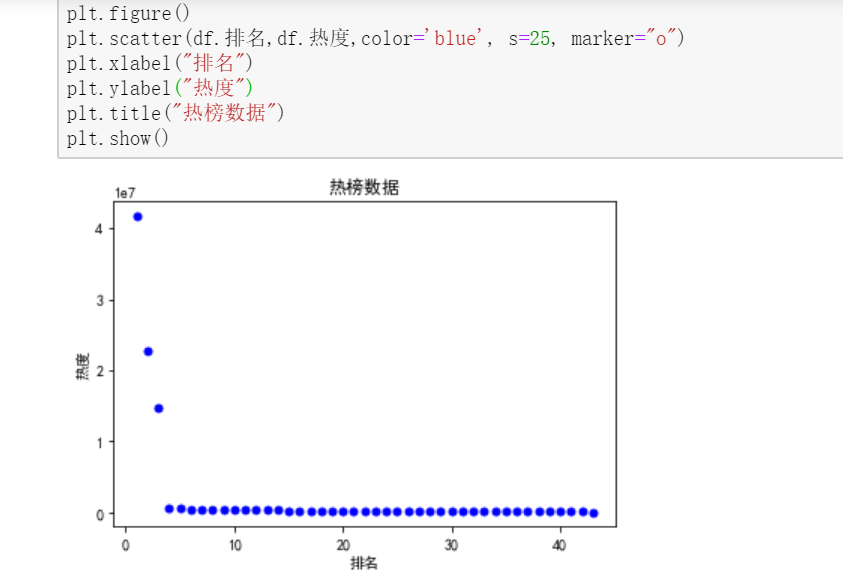
散点图 #绘制散点图 plt.figure() plt.scatter(df.排名,df.热度,color='blue', s=25, marker="o") plt.xlabel("排名") plt.ylabel("热度") plt.title("热榜数据") plt.show()
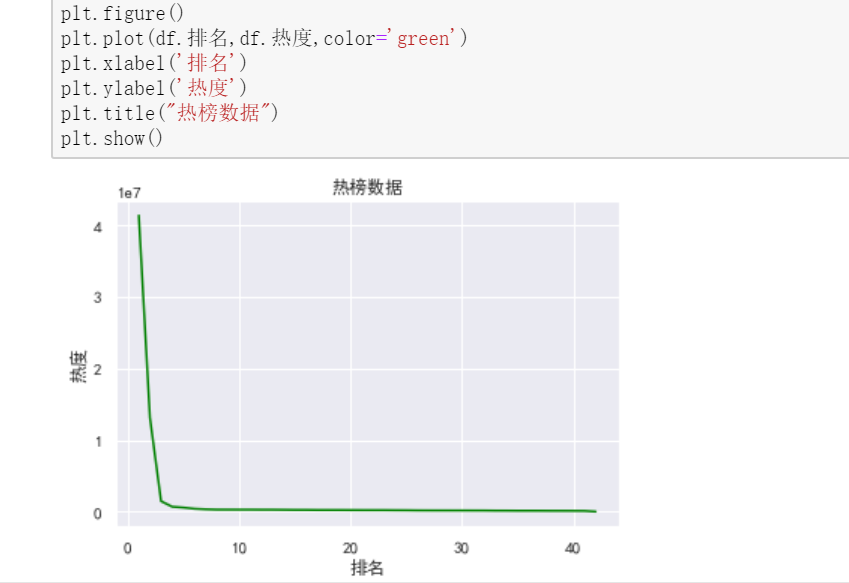
折线图 #绘制折线图 plt.figure() plt.plot(df.排名,df.热度,color='green') plt.xlabel('排名') plt.ylabel('热度') plt.title("热榜数据") plt.show()
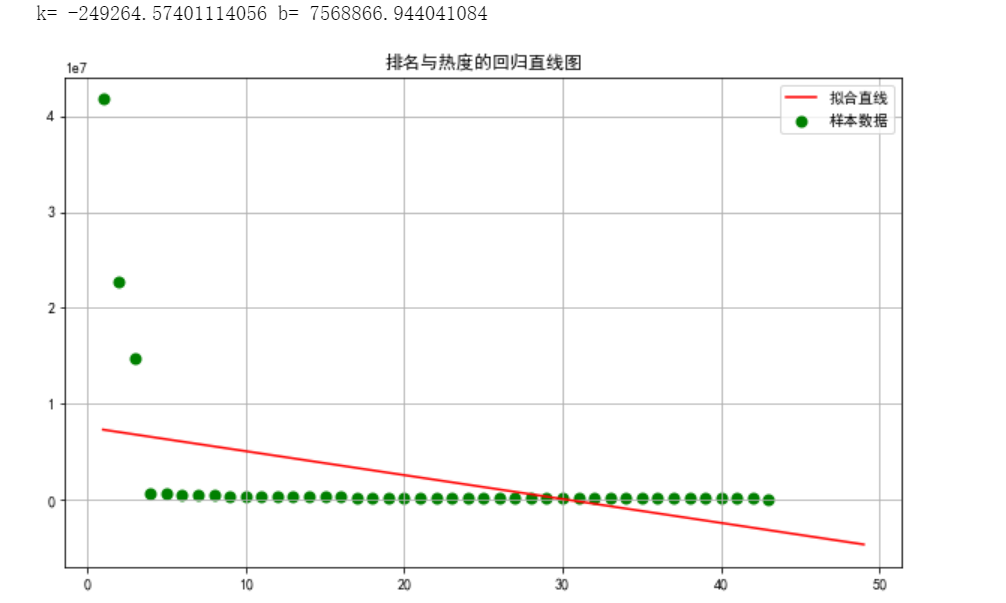
4.建立排名与热度之间的回归方程 import numpy as np import scipy as sp import matplotlib.pyplot as plt import matplotlib from scipy.optimize import leastsq from numpy import genfromtxt X=df.排名 Y=df.热度 #构建一元一次方程 def func(p,x): k,b=p return k*x+b #设置误差函数 def error_func(p,x,y): return func(p,x)-y p0=[1,0] Para=leastsq(error_func,p0,args=(X,Y)) k,b=Para[0] print("k=",k,"b=",b) #设置画布大小 plt.figure(figsize=(10,6)) #绘制数据散点分布图 plt.scatter(X,Y,color="green",label=u"样本数据",linewidth=2) #绘制拟合直线 x=np.linspace(1,49,50) y=k*x+b plt.plot(x,y,color="red",label=u"拟合直线") plt.legend() plt.title("排名与热度的回归直线图") plt.grid() plt.show()
5.代码总汇 import requests from bs4 import BeautifulSoup import bs4 #定义获取页面信息函数 def get_html(url,headers): r = requests.get(url,headers=headers) r.encoding = r.apparent_encoding#解决中文字符编码问题 return r.text #建立空表格 准备数据填充 name=[] rank=[] times=[] #定义解析页面函数 def get_pages(html): soup = BeautifulSoup(html,'html.parser')#使用BeautifulSoup库解析页面 all_topics=soup.find_all('tr')[1:] #获取标签内容 for each_topic in all_topics: topic_times = each_topic.find('td',class_='last')#热度 topic_rank = each_topic.find('td',class_='first')#排名 topic_name = each_topic.find('td',class_='keyword')#标题目 if topic_rank != None and topic_name!=None and topic_times!=None: topic_rank = each_topic.find('td',class_='first').get_text().replace(' ','').replace('\n','') rank.append(topic_rank)#填充数据 topic_name = each_topic.find('td',class_='keyword').get_text().replace(' ','').replace('\n','') name.append(topic_name) topic_times = each_topic.find('td',class_='last').get_text().replace(' ','').replace('\n','') times.append(topic_times) tplt = "排名:{0:^4}\t标题:{1:{3}^15}\t热度:{2:^8}" #定义主函数 def main(): url = 'http://top.baidu.com/buzz?b=1&fr=20811' headers= {'User-Agent':'Mozilla/5.0'}#表头信息 html = get_html(url,headers) get_pages(html) if __name__=='__main__': main() print(times) print(name) print(rank) #使用pandans保存数据 from pandas.core.frame import DataFrame D={"排名":rank, "标题":name, "热度":times} data=DataFrame(D) print(data) #生成CSV文件 filename="redian.csv" data.to_csv(filename,index=False) import pandas as pd #读取文件 df=pd.DataFrame(pd.read_csv('redian.csv')) print(df) #删除无效列与行 df.drop('标题', axis=1, inplace = True) df.head() #重复值处理 df.duplicated() #空值与缺失值处理 print(df['热度'].isnull().value_counts()) df[df.isnull().values==True] #异常值处理 df.describe() #数据处理与可视化 import numpy as np import pandas as pd import sklearn from sklearn.linear_model import LinearRegression X=df.drop("排名",axis=1) predict_model=LinearRegression() #训练模型 predict_model.fit(X,df['热度']) #判断相关性 print("回归系数为:",predict_model.coef_) #排名与热度的回归图 import seaborn as sns sns.regplot(df.排名,df.热度) sns.set(font='SimHei') # 解决Seaborn中文显示问题 #绘制柱状图 import pandas as pd import numpy as np import matplotlib.pyplot as plt plt.rcParams['font.sans-serif']=['SimHei'] #用来正常显示中文标签 plt.rcParams['axes.unicode_minus']=False #用来正常显示负号 plt.figure() plt.bar(df.排名,df.热度,color='green') plt.xlabel('排名') plt.ylabel('热度') plt.title("热榜数据") plt.show() #绘制散点图 plt.figure() plt.scatter(df.排名,df.热度,color='blue', s=25, marker="o") plt.xlabel("排名") plt.ylabel("热度") plt.title("热榜数据") plt.show() #绘制折线图 plt.figure() plt.plot(df.排名,df.热度,color='green') plt.xlabel('排名') plt.ylabel('热度') plt.title("热榜数据") plt.show() #建立排名和热度之间的回归方程 import numpy as np import scipy as sp import matplotlib.pyplot as plt import matplotlib from scipy.optimize import leastsq from numpy import genfromtxt X=df.排名 Y=df.热度 #构建一元一次方程 def func(p,x): k,b=p return k*x+b #设置误差函数 def error_func(p,x,y): return func(p,x)-y p0=[1,0] Para=leastsq(error_func,p0,args=(X,Y)) k,b=Para[0] print("k=",k,"b=",b) #设置画布大小 plt.figure(figsize=(10,6)) #绘制数据散点分布图 plt.scatter(X,Y,color="green",label=u"样本数据",linewidth=2) #绘制拟合直线 x=np.linspace(1,49,50) y=k*x+b plt.plot(x,y,color="red",label=u"拟合直线") plt.legend() plt.title("排名与热度的回归直线图") plt.grid() plt.show()四、结论 1..经过对主题数据的分析与可视化,可以更加清晰的看出排名与热度之间的关系,排名越靠前的热度越高。数据的分析与可视化有助于对数据的理解与分析,让我们更直观的看出数据之间的关系。 2.小结:通过这次的程序设计任务,我深刻的认识到自己的不足,在过程中遇到了很多困难,通过查阅课本、回看老师上课视频、百度搜索不断解决了遇到的问题,也学会了很多东西,更提高了对python的兴趣。 |

 三、网络爬虫程序设计
三、网络爬虫程序设计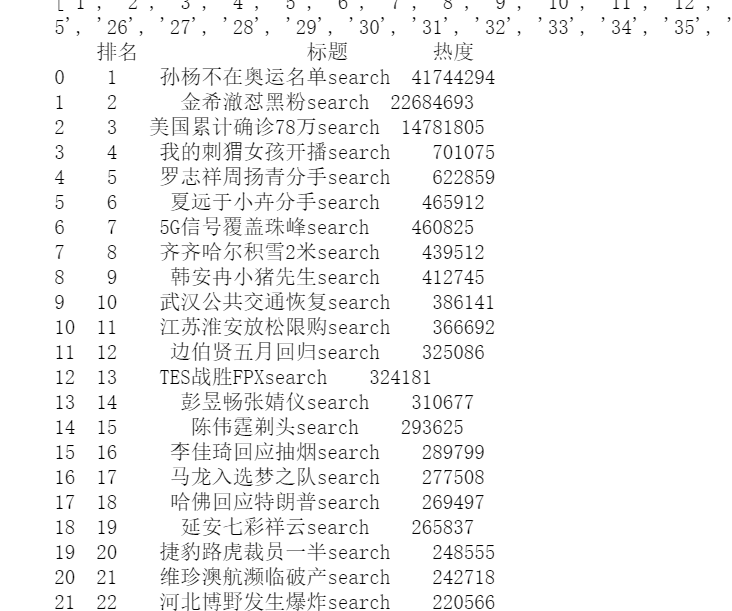

【本文地址】
今日新闻 |
推荐新闻 |